Portfolio · Case Study

Diego S.
AI Engineering
RAG Systems
Content Automation
Agentic Pipelines
Education
Florida International University
BS · Computer Science
Florida International University
MBA · Marketing & E-Commerce
Pennsylvania State University
Master of Applied Statistics
Available now
100%Job Success
Case Study
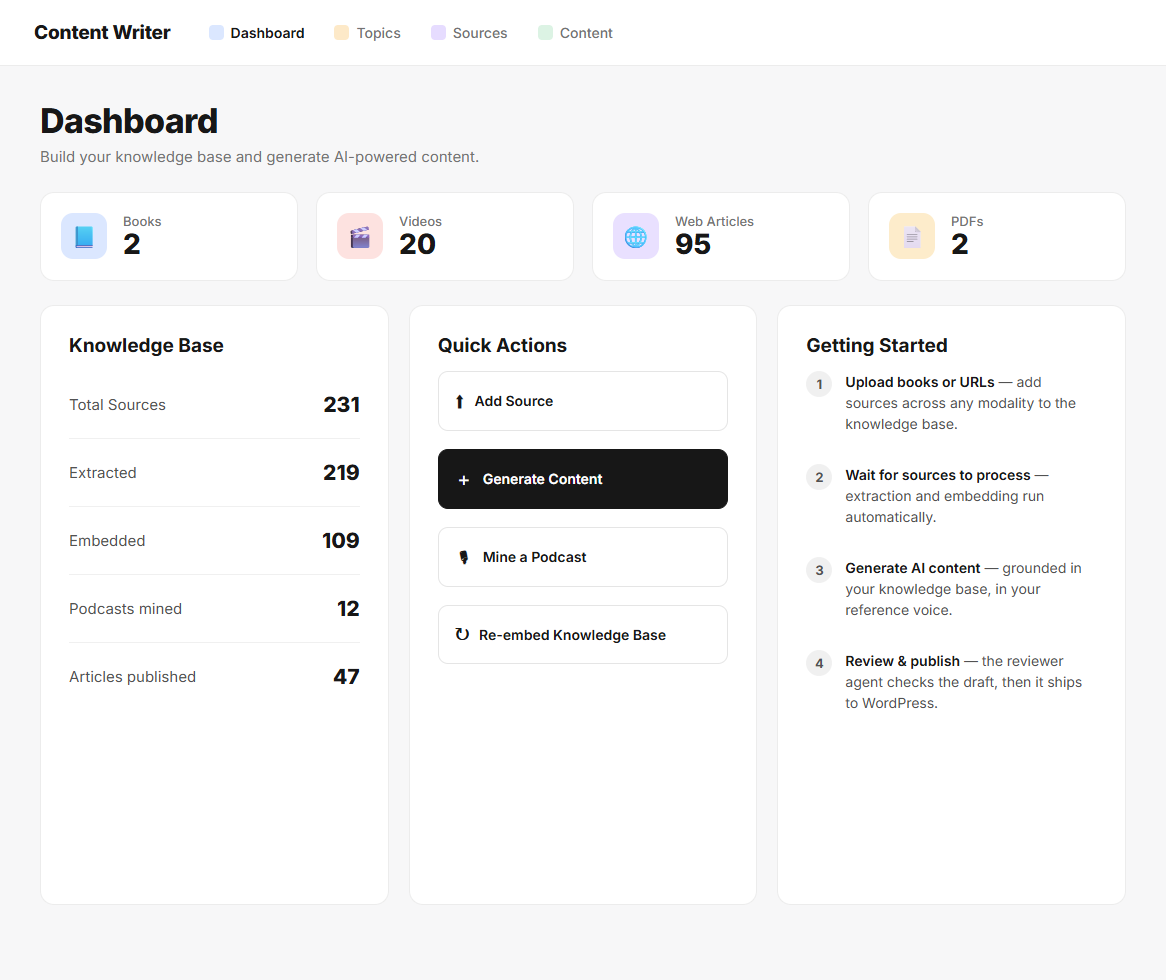
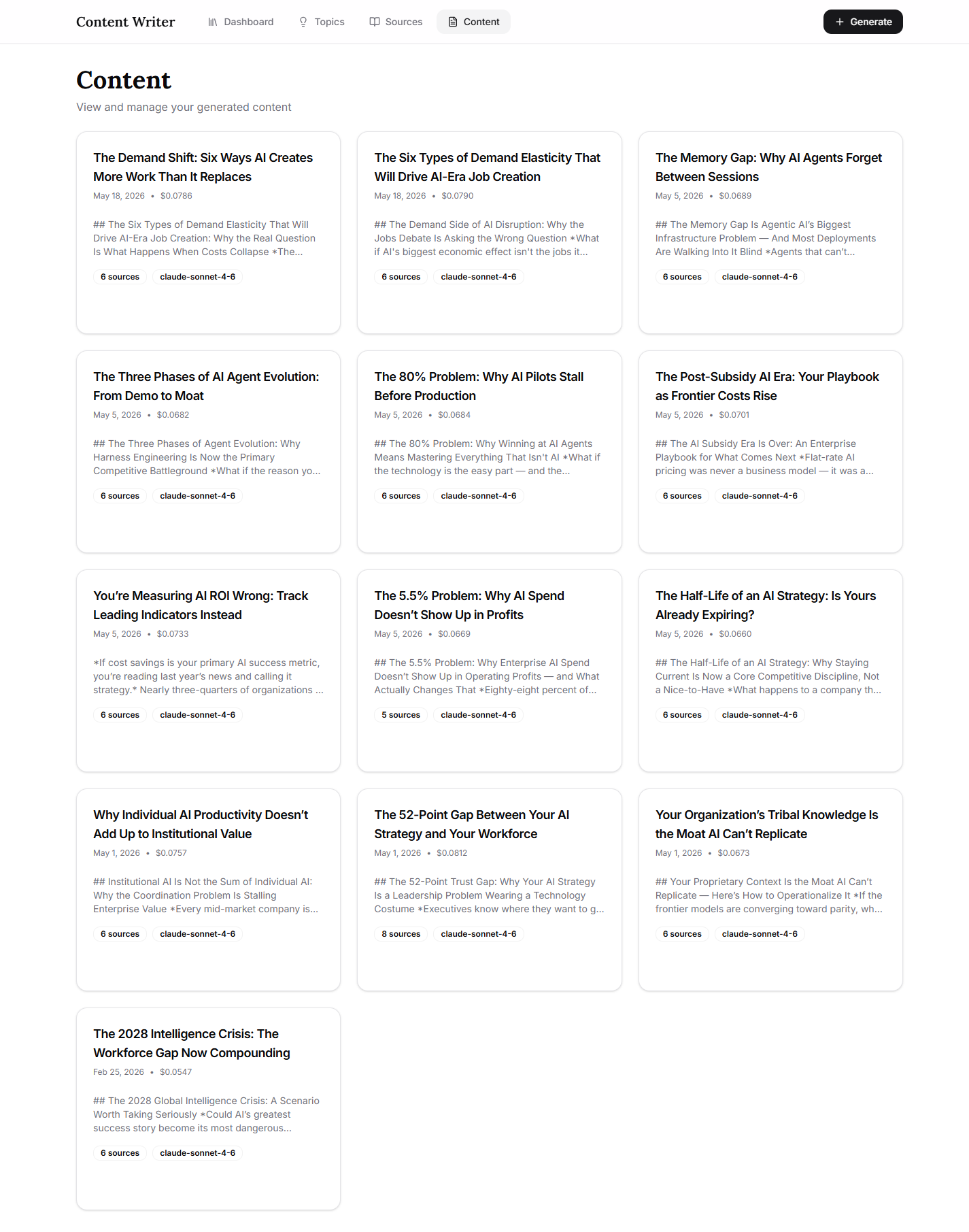
AI Content Marketing Engine
5
Content source types
4
Output channels
3
AI models in pipeline
01 · 08